
Google’s FloC was killed because it was a bad idea for privacy on the web. But we didn’t know exactly how bad until two MIT researchers tested it — over months, using technical approaches and an expensive, private dataset. That it was this difficult to add some transparency is unacceptable for a fundamental change to the web that would impact the majority of browser users. For the future of the internet to be more decentralized, accessible, and private, proposals like FLoC (and the recent Topics) need to come with tools that researchers — and the public — can use to provide meaningful feedback.
As the internet has evolved from a research tool to a profit-driven ecosystem, the machinery that drives it has become increasingly centralised. The internet today is almost unrecognizable from the decentralized, fragmented networks of the ‘90s. Its reorganization, which began in the early 2000s, was catapulted by one of the most transformative inventions of the digital era: online ad auctions. Until 2002, when this invention finally made Google profitable, Google had a search engine but no method for monetising attention. Shoshanna Zuboff, in her now near-biblical Age of Surveillance Capitalism, argues that this became the turning point for capital as well as the internet. It helped invent “behavioural surplus,” the material created from our own banal behaviour on the web that fuels the multi-billion dollar digital ad market.
This is the invention that made Google the titan it is today, catapulted Mark Zuckerberg into stratospheric wealth, and forms the backbone of the now deeply centralised, surveillant web. Together, Facebook and Google claimed over 54% of the digital ad market in 2020. New privacy rules are chipping away at ad infrastructure’s foundations, but these same forces and companies are the ones rebuilding it — with little oversight — through new proposals that change how the internet works. To ensure a better future for the web, projects that change fundamental infrastructure need to be packaged with tools that researchers — and the public — can use to provide meaningful feedback.
One of the core technologies that has facilitated our centralised, surveillant, highly invasive present is the “third-party” cookie. Third-party cookies let domains other than the websites you are currently visiting create traces of your behaviour. This allows advertising companies to create rich profiles of your browsing history, collect details of what items you browsed on a shopping site, and more. Years of (extremely profitable) development and network-building around this technology has given birth to a monolithic, opaque industry that can observe at least 91% of an average user’s browsing history and up to 90% of the behaviour from users who employ ad-blockers.
So when, in 2020, Google announced that it would disable third-party cookies in the Chrome browser in response to mounting pressure and campaigns around user privacy, it needed to come up with another solution that would also maintain its profitable network of web advertisers. Google developers proposed a method, Federated Learning of Cohorts (FLoC), which was pitched as a way to enable interest-based advertising while mitigating the risks of individualized tracking that third-party cookies created. To do this, browsers would use the FLoC algorithm to compute a user’s “interest cohort” based on their browsing history. Each cohort contains thousands of users with similar recent browsing history, and this cohort ID is then the thing that is made available to advertisers. The idea behind FLoC is that this cohort ID could be used to bombard you with ads, rather than the specific details of your browsing history. Google’s trial run of FLoC in 2021 showed that revenue for advertisers would largely stay the same, a huge win for Google and the ad networks.
But what was the cost for users? How private was FLoC, really? Privacy researchers at Mozilla and the Electronic Frontier Foundation quickly raised important questions about FloC that had few answers. What if an advertiser or attacker could use your cohort ID to learn something about your race or gender? How likely would that be? Could cohort IDs actually give advertisers extra information they could use to uniquely identify you? Without additional research from Google, answering these questions was a theoretical exercise, rather than empirical research. For their part, a team at Google did examine some of the risks of FLoC using empirical data from their pilot, but their analysis was limited.
This past fall, my colleague Alex Berke and I set out to independently test some of the privacy community’s lingering questions about FLoC. Our analysis showed that within four weeks, over 95% of users could be uniquely identified using just their cohort IDs. This means that after only a few weeks, FLoC would have easily let the ad industry track people across the web, largely defeating the purpose of FLoC entirely. We also found that, surprisingly, cohort IDs did not correlate with race, a good thing for those worried about FLoC being used for predatory and discriminatory advertising.
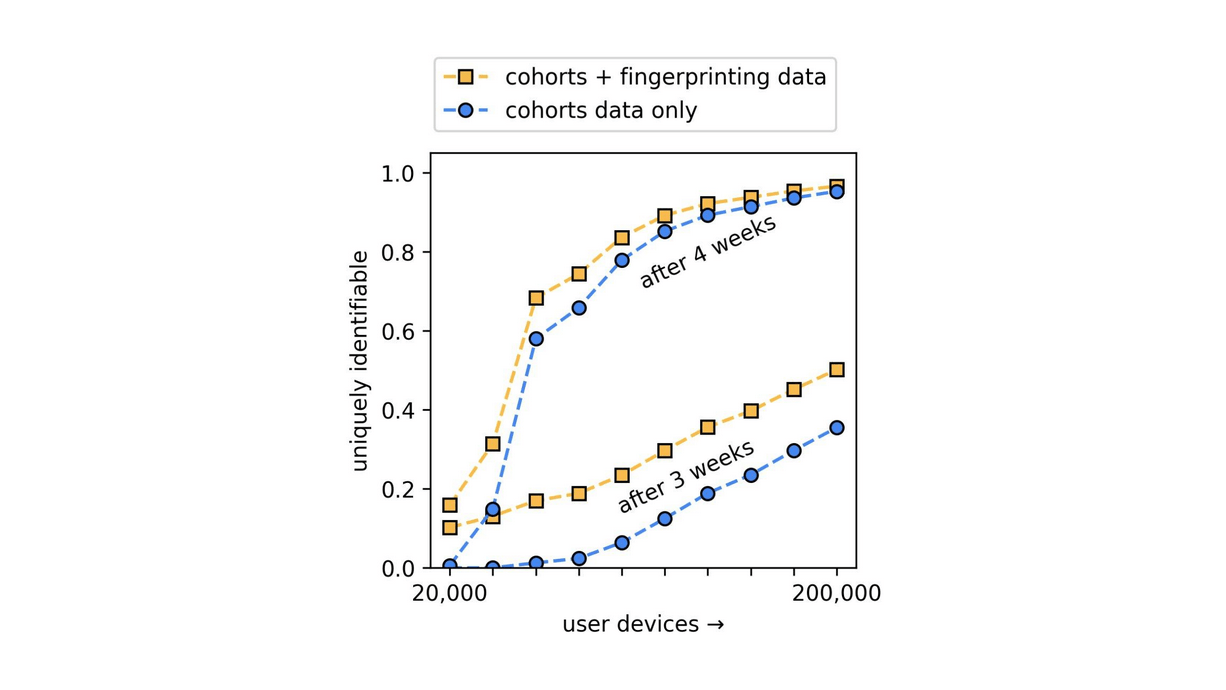
But our analysis has a crucial problem. We used a dataset of browsing histories that we were able to obtain through a research lab at Harvard that, while expensive, is severely limited. While our dataset captured browsing data from over 90,000 devices across the U.S., Google’s origin trial included at least 60 million users. If we ran our same analysis on Google’s data, there’s a chance we might find radically different results. But — we can’t. When we opened an issue on Github detailing our findings and asking for Google to release some code or datasets so independent researchers like us could test new proposals, we were told that there was no public dataset of browsing histories they could recommend.
There are a dizzying array of other questions that we could ask with access to datasets from Google or other online ad marketplaces. Tim Hwang, in his 2020 book, Subprime Attention Crisis, makes the strong case that online advertising is a bubble waiting to be popped, propped up on false claims of advertising’s effectiveness and measurability. Hwang cites many cases where firms pivoting from personalised online ads to traditional advertising channels increased their messaging reach while reducing spending. Better public analysis of these kinds of experiments could do more than test the privacy claims of future “fixes” to online ads; they could offer much-needed transparency into the value of online ads in the first place.
And the data isn’t the only problem. While I understand that Google can’t just provide browsing histories from Chrome users, proposals like FLoC and Topics might fundamentally alter the way the web works, for everyone. It took months for Alex and me, two MIT graduate students, to re-implement FLoC, process (and get access to) an external dataset of browsing histories, and run our analysis. We are the only team besides Google that has published any empirical work examining FLoC at all — because it is hard. It shouldn’t be.
Yet another downstream effect of the web’s centralization is the gatekeeping of tools, data, infrastructure, and research that guides its future. This gatekeeping is a feature of centralization, not a bug. But it doesn’t have to be this way. Major companies like Google could publish open toolkits that let researchers like us ask a barrage of questions of new technologies. They could launch a research program, providing limited data access from their trials to researchers interested in asking their own questions about new proposals like FLoC. Better yet, they could create open, creative tools that invite broader participation in what the future of advertising on the web should look like.
But why would they? They don’t have any incentive. Regulation like Europe’s GDPR and California’s CCPA only push firms like Google to replace third-party cookies and protect (to a degree) user data. Making the process of decision-making, testing, and knowledge creation more open isn’t on the regulatory radar. Yet, the public has a deep vested interest in online ad markets that extends beyond privacy. Like the creation of the first online ad markets, how they will operate in the future will have major implications for the core infrastructure of the web.
Additional contributions by Alex Berke.